
What is Retrieval Augmented Generation?
If you have been looking up data in a vector store or some other database and passing relevant info to LLM as context when generating output, you are already doing retrieval augmented generation. Retrieval augmented generation or RAG for short is the architecture popularized by Meta in 2020 that aims to improve the performance of LLMs by passing relevant information to the model along with the question/task details.
Why RAG?
LLMs are trained on large corpuses of data and can answer any questions or complete tasks using their parameterized memory. These models have a knowledge cutoff dates depending on when they were last trained on. When asked a question out of its knowledge base or about events that happened after the knowledge cutoff date, there is a high chance that the model will hallucinate. Researchers at Meta discovered that by providing relevant information about the task at hand, the model’s performance at completing the task improves significantly.
For example, if the model is being asked about an event that happened after the cutoff date, providing information about this event as context and then asking the question will help the model answer the question correctly. Because of the limited context window length of LLMs, we can only pass the most relevant knowledge for the task at hand. The quality of the data we add in the context influences the quality of the response that the model generates. There are multiple techniques that ML practitioners use in different stages of a RAG pipeline to improve LLM’s performance.
RAG vs Fine-tuning
Fine-tuning is the process of training a model on a specific task like how one can fine-tune GPT-3.5 on a question answering dataset to improve its performance on question answering for that specific dataset. Fine-tuning is a good approach if you have a dataset large enough for the task at hand and the dataset doesn't change. If the dataset is dynamic, we will need to keep retraining the model to keep up with the changes. Fine-tuning is also not a good approach if you don’t have a large dataset for the task at hand. In such cases, you can use RAG to improve the performance of LLMs. Similarly you can use RAG to improve the performance of LLMs on tasks like summarization, translation etc. that may not be possible to fine-tune on.
How it works?
RAG architecture and the pipeline involves three main stages - data preparation, retrieval and generation. The data preparation stage involves identifying the data sources, extracting the data from the sources, cleaning the data and storing it in a database. The retrieval stage involves retrieving relevant data from the database based on the task at hand. The generation stage involves generating the output using the retrieved data and the task at hand. The quality of the output depends on the quality of the data and the retrieval strategy. The following sections describe each stage in detail.
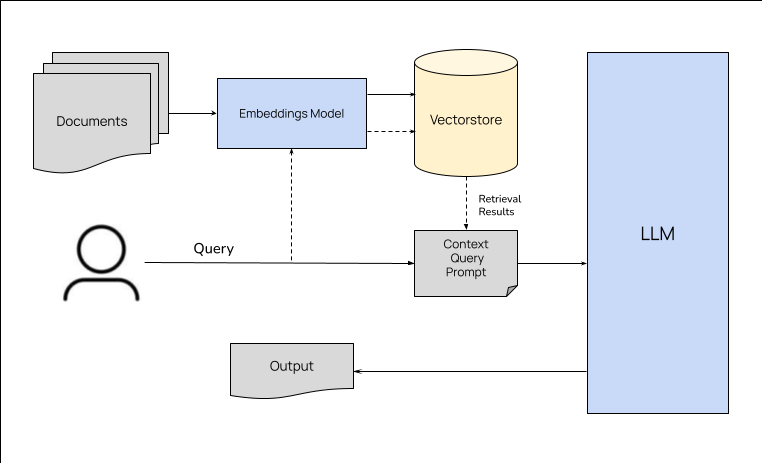
Data Preparation
Based on the type of tasks LLM is going to handle, data preparation usually involves identifying the data sources, extracting the data from the sources, cleaning the data and storing it in a database. The kind of database being used to store the data and the steps involved in preparing the data can vary depending on the use case and the retrieval methods. For example, if you are using a vector store like Weaviate, you will need to create embeddings for the data and store them in the vector store. If you are using a search engine like Elasticsearch, you will need to index the data in the search engine. If you are using a graph database like Neo4j, you will need to create nodes and edges for the data and store them in the graph database. We will discuss the different types of databases and the steps involved in preparing the data in the next section.
Vector Store
Vector stores are useful for storing unstructured data like text, images, audio etc. and for searching the data based on semantic similarity. An embedding model is used to generate vector embeddings for the data we store in the database. Data will need to be chunked into smaller pieces depending on the type of data, use case and the embedding model. For example, if you are storing text data, you can chunk the data into sentences or paragraphs. If the you are storing code, you can chunk the data into functions or classes. You may use smaller chunks if you choose to provide a wide range of snippets in context to the LLM. Once the data is chunked, you can generate embeddings for each chunk and store them in the vector store. When a query is made to the vector store, the query is also converted into an embedding and the vector store returns the most similar embeddings to the query.
Vector databases like Weaviate will take care of generating embeddings during both storage and retrieval and you can just focus on data modeling and chunking strategies.
Keyword Search
Keyword search is a simple approach to retrieving data where the data is indexed based on keywords and the search engine returns the documents that contain the keywords. Keyword search is useful for storing structured data like tables, documents etc. and for searching the data using keywords.
Graph Database
Graph databases store data in the form of nodes and edges. They are useful for storing structured data like tables, documents etc. and for searching the data using relationships between the data. For example, if you are storing data about people, you can create nodes for each person and edges between people who know each other. When a query is made to the graph database, the graph database returns the nodes that are connected to the query node. This kind of retrieval where the knowledge graphs are used is useful for tasks like question answering where the answer is a person or an entity.
Search Engine
Data in a RAG pipeline could be retrieved from public search engines like Google, Bing etc or internal search engines like Elasticsearch, Solr etc. During retrieval stage in RAG architecture, the search engine is queried with the question/task details and the search engine returns the most relevant documents. Search engines are useful for retrieving data from the web and for searching the data with keywords. Data from a search engine can be combined with data from other databases like vector stores, graph databases etc. to improve the quality of the output.
Hybrid approaches that combine multiple strategies (like semantic search + keyword matches) are also possible and are known to give better results for most use cases. For example, you can use a vector store to store text data and a graph database to store structured data and combine the results from both databases to generate the output.
Retrieval
Once the data is identified and processed to be ready for retrieval, RAG pipeline involves retrieving the relevant data based on the task (question asked by user) being handled and preparing the context to be passed to the generator. Retrieval strategy can vary depending on the use case. It usually involves passing the user's query or task to the datastore and pulling relevant results. For example, if we are building a question answering system with a vector database storing the chunks of related data, we can generate embeddings for the user's query, do a similarity search for the embeddings in the vector database and retrieve the most similar chunks (some vector databases takes care of generating embeddings during retrieval). Similarly depending on the use case, we can do a hybrid search on the same vector store or with multiple databases and combine the results to pass as context to the generator.
Generation
Once the relevant data is retrieved, it is passed to the generator (LLM) along with the user's query or task. The LLM generates the output using the retrieved data and the user's query or task. The quality of the output depends on the quality of the data and the retrieval strategy. The instructions for generating the output will also greatly impact the quality of the output.
Techniques to improve RAG performance in production
Following are some techniques across the different stages of RAG pipeline that can be used to improve the performance of RAG in production.
-
Hybrid search: Combining semantic search with keyword search to retrieve relevant data from a vector store is known to give better results for most use cases.
-
Summaries: It may be beneficial to summarize the chunks and storing the summaries in the vector store instead of raw chunks. For example, if your data involves a lot of filler words, it is a good idea to summarize the chunks to remove the filler words and store the summaries in the vector store. This will improve the quality of generation since we are removing the noise from the data as well as help with reducing the number of tokens in the input.
-
Overlapping chunks: When splitting the data into chunks for semantic retrieval, there could be instances with semantic search where we may pick a chunk which may have related and useful context in the neighboring chunks. Passing this chunk to the LLM for generation without surrounding context may result in poor quality output. To avoid this, we can overlap the chunks and pass the overlapping chunks to the LLM for generation. For example, if we are splitting the data into chunks of 100 tokens, we can overlap the chunks by 50 tokens. This will ensure that we are passing the surrounding context to the LLM for generation.
-
Fine-tuned embedding models: Using off-the-shelf embedding models like BERT, ada etc to generate embedding for the data chunks may work for most use-cases. But if you are working on a specific domain, these models may not represent the domain well in the vector space resulting in poor quality retrieval. In such cases, we can fine-tune and use an embedding model on the data from the domain to improve the quality of retrieval.
-
Metadata: Providing metadata like source etc., about the chunks being passed in the context will help the LLM understand the context better resulting in better output generation.
-
Re-ranking: When using semantic search, it is possible that the top-k results are similar to each other. In such cases, we should consider re-ranking the results based on other factors like metadata, keyword matches etc. to cover a wide range of snippets in context to the LLM.
-
Lost in the middle: It has been observed that LLMs do not place equal weight to all the tokens in the input. Tokens in the middle appear to have been given less weight than the tokens at the beginning and end of the input. This is known as the lost in the middle problem. To avoid this, we can re-order the context snippets so we place the most important snippets at the beginning and end of the input and the less important snippets in the middle.
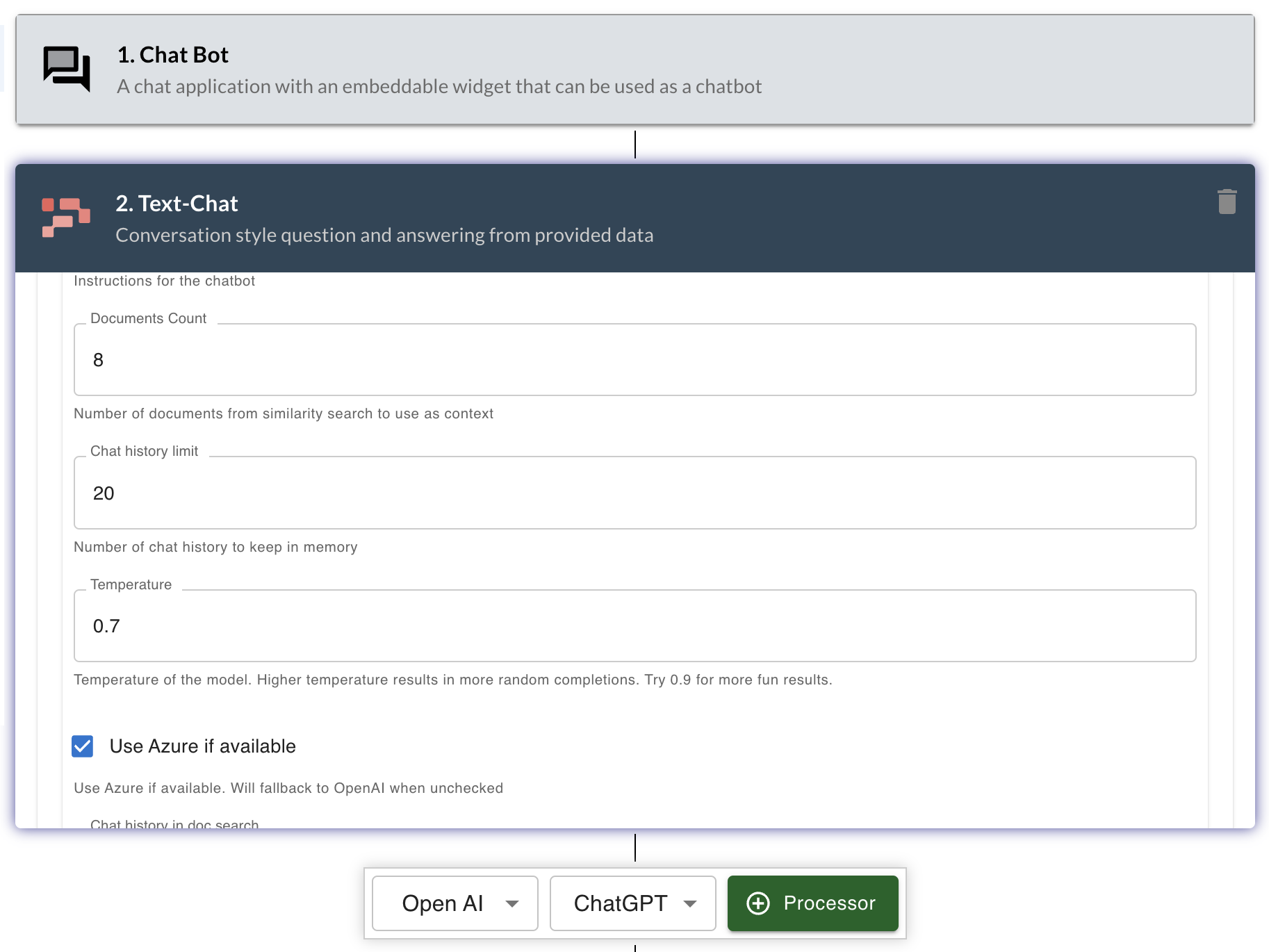
RAG in LLMStack
RAG pipeline comes out of the box with LLMStack. When you create a datasource and upload data, LLMStack takes care of chunking the data, generating embeddings and storing them in the vector store. When you create an app that uses Text-Chat processor, LLMStack takes care of retrieving the relevant data from the vector store and passing it to the LLM for generation. Templates like Website Chatbot, AI Augmented Search, Brand Copy Checker etc., are all using RAG pipeline in LLMStack.
Conclusion
RAG has proven to be a simple yet powerful approach that can be used to improve the performance of LLMs on a wide range of tasks. With researchers and practitioners working on improving the different stages of RAG pipeline, we can expect to see more use cases of RAG in production in the near future. If you are interested in leveraging RAG in your work, you can try out LLMStack at https://github.com/trypromptly/LLMStack or with our cloud offering, Promptly.